After the Panzer Dragoon Saga translation to spanish we choose this RPG to make another one.
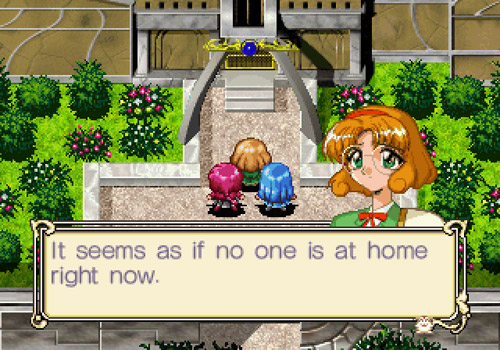
All the things seems go all right, I mean we have the full script translated, the ingame font hacked and all ready to make the insertion and then the patch.
But we have the last problem, is the diary of the 3 girls starring the game. As you maybe know this diary are images with an style like handwriting. Very cool, but very hard to modify
Some examples:


The images are somehow encoded or compressed and we can't edit it in the normal way. We found a japanese utilty named ENIKKIAT.EXE that allows to open and view the images in DOS mode.
But still we can't export it or regenerate again the edited ones.... Then we can't complete the translation....
I atach some files of the diary, seems to there is some images in each files, like a some container file, I suppose.
Atach the japanese utility too... maybe can help in any way...
http://rapidshare.com/files/320381330/DIARY.rar
Thanks guys, you helped so much with the font of Panzer Dragoon Saga I hope you can done it again.
THANKS in advanced!
All the things seems go all right, I mean we have the full script translated, the ingame font hacked and all ready to make the insertion and then the patch.
But we have the last problem, is the diary of the 3 girls starring the game. As you maybe know this diary are images with an style like handwriting. Very cool, but very hard to modify
Some examples:
The images are somehow encoded or compressed and we can't edit it in the normal way. We found a japanese utilty named ENIKKIAT.EXE that allows to open and view the images in DOS mode.
But still we can't export it or regenerate again the edited ones.... Then we can't complete the translation....
I atach some files of the diary, seems to there is some images in each files, like a some container file, I suppose.
Atach the japanese utility too... maybe can help in any way...
http://rapidshare.com/files/320381330/DIARY.rar
Thanks guys, you helped so much with the font of Panzer Dragoon Saga I hope you can done it again.
THANKS in advanced!

 but I think maybe some of our friends can use this valuable info to make it works...
but I think maybe some of our friends can use this valuable info to make it works...